大文件怎么快速上传?最实用的实现方法!(大文件怎么快速上传?最实用的实现方法是)
admin227856年前0条评论
年夜文件快速上传的计划,置信你也有过了解,实在无非便是将文件变小,也便是通过压缩文件资本或者文件资本分块后再上传。
本文只介绍资本分块上传的形式,而且会通过前端(vue3 +vite)以及效劳端(nodejs +koa2)交互的形式,实现年夜文件分块上传的轻易性能。
梳理思路
问题1:谁卖命资本分块?谁卖命资本整合?
固然这个问题也很轻易,一定是前端卖命分块,效劳端卖命整合。
问题2:前端怎么对于资本停止分块?
首先是抉择上传的文件资本,接着就能够失去对于应的文件工具File,而File.prototype.slice方法能够实现资本的分块,固然也有人说是Blob.prototype.slice方法,因为 Blob.prototype.slice === File.prototype.slice。
问题3:效劳端怎么通晓甚么时刻要整合伙源?怎样保障资本整合的有序性?
因为前端会将资本分块,而后单独发送申请,也便是说,本来1个文件对于应1个上传申请,现在能够会变为1个文件对于应n个上传申请,所曩昔端能够基于Promise.all将这多个接口整合,上传实现在发送一个离开的申请,照顾效劳端停止离开。
离开时可通过nodejs中的读写流(readStream/writeStream),将所有切片的流通过管道(pipe)输入终究文件的流中。
在发送申请资本时,前端会定好每一个文件对于应的序号,并将以后分块、序号以及文件hash等信息一起发送给效劳端,效劳端在停止离开时,通过序号停止顺序离开就可。
问题4:如果某个分块的上传申请失利了,怎么办?
一旦效劳端某个上传申请失利,会返回以后分块失利的信息,其中会蕴含文件名称、文件hash、分块巨细以及分块序号等,前端拿到这些信息后能够停止重传,同时思考此时是否需要将Promise.all调换为Promise.allSettled更不便。
前端整体
建立名目
通过pnpmcreatevite建立名目,对于应文件目录下列.
申请模块
src/request.js
该文件便是针对于axios停止轻易的封装,下列:
- import axios from "axios";
- const baseURL = 'http://localhost:3001';
- export const uploadFile = (url, formData, onUploadProgress = () => { }) => {
- return axios({
- method: 'post',
- url,
- baseURL,
- headers: {
- 'Content-Type': 'multipart/form-data'
- },
- data: formData,
- onUploadProgress
- });
- }
- export const mergeChunks = (url, data) => {
- return axios({
- method: 'post',
- url,
- baseURL,
- headers: {
- 'Content-Type': 'application/json'
- },
- data
- });
- }
文件资本分块
依据DefualtChunkSize=5*1024*1024,即5MB,来对于文件停止资本分块停止盘算,通过spark-md5[1]依据文件内容盘算出文件的hash值,不便做其余优化,比如:当hash值稳定时,效劳端不需要重复读写文件等。
- // 获取文件分块
- const getFileChunk = (file, chunkSize = DefualtChunkSize) => {
- return new Promise((resovle) => {
- let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice,
- chunks = Math.ceil(file.size / chunkSize),
- currentChunk = 0,
- spark = new SparkMD5.ArrayBuffer(),
- fileReader = new FileReader();
- fileReader.onload = function (e) {
- console.log('read chunk nr', currentChunk + 1, 'of');
- const chunk = e.target.result;
- spark.append(chunk);
- currentChunk++;
- if (currentChunk = file.size) ? file.size : start + chunkSize;
- let chunk = blobSlice.call(file, start, end);
- fileChunkList.value.push({ chunk, size: chunk.size, name: currFile.value.name });
- fileReader.readAsArrayBuffer(chunk);
- }
- loadNext();
- });
- }
发送上传申请以及离开申请
通过Promise.all方法整合以是分块的上传申请,在所有分块资本上传完毕后,在then中发送离开申请。
- // 上传申请
- const uploadChunks = (fileHash) => {
- const requests = fileChunkList.value.map((item, index) => {
- const formData = new FormData();
- formData.append(`${currFile.value.name}-${fileHash}-${index}`, item.chunk);
- formData.append("filename", currFile.value.name);
- formData.append("hash", `${fileHash}-${index}`);
- formData.append("fileHash", fileHash);
- return uploadFile('/upload', formData, onUploadProgress(item));
- });
- Promise.all(requests).then(() => {
- mergeChunks('/mergeChunks', { size: DefualtChunkSize, filename: currFile.value.name });
- });
- }
进度条数据
分块进度数据应用axios中的onUploadProgress配置项获取数据,通过应用computed依据分块进度数据的变化主动主动盘算以后文件的总进度。
- // 总进度条
- const totalPercentage = computed(() => {
- if (!fileChunkList.value.length) return 0;
- const loaded = fileChunkList.value
- .map(item => item.size * item.percentage)
- .reduce((curr, next) => curr + next);
- return parseInt((loaded / currFile.value.size).toFixed(2));
- })
- // 分块进度条
- const onUploadProgress = (item) => (e) => {
- item.percentage = parseInt(String((e.loaded / e.total) * 100));
- }
效劳端整体
搭建效劳
应用koa2搭建轻易的效劳,端口为3001
应用koa-body解决接受前端通报 'Content-Type': 'multipart/form-data' 范例的数据
应用koa-router注册效劳端路由
应用koa2-cors解决跨域问题
目录/文件分别
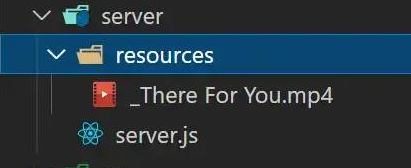
server/server.js
该文件是效劳审察细的代码实现,用于解决接受以及整合分块资本。
server/resources
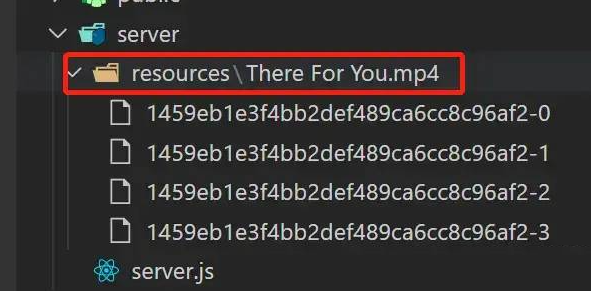
该目录是用于寄存单文件的多个分块,以及最后分块整合后的资本:
分块资本未离开时,会在该目录下以以后文件名建立一个目录,用于寄存这个该文件相干的所有分块
分块资本需离开时,会读取这个文件对于应的目录下的所有分块资本,而后将它们整剖析原文件
分块资本离开实现,会删除了这个对于应的文件目录,只生存离开后的原文件,天生的文件名比实在文件名多一个 _ 前缀,如原文件名 "测试文件.txt" 对于应离开后的文件名 "_测试文件.txt"
接受分块
应用 koa-body 中的 formidable 配置中的 onFileBegin 函数解决前端传来的 FormData 中的文件资本,在前端解决对于应分块名时的体例为:filename-fileHash-index,以是这里间接将分块名拆分就可获取对于应的信息。
- // 上传申请
- router.post(
- '/upload',
- // 解决文件 form-data 数据
- koaBody({
- multipart: true,
- formidable: {
- uploadDir: outputPath,
- onFileBegin: (name, file) => {
- const [filename, fileHash, index] = name.split('-');
- const dir = path.join(outputPath, filename);
- // 生存以后 chunk 信息,发生同伴时停止返回
- currChunk = {
- filename,
- fileHash,
- index
- };
- // 检察文件夹是否存在如果不存在则新建文件夹
- if (!fs.existsSync(dir)) {
- fs.mkdirSync(dir);
- }
- // 遮蔽文件寄存的完好门路
- file.path = `${dir}/${fileHash}-${index}`;
- },
- onError: (error) => {
- app.status = 400;
- app.body = { code: 400, msg: "上传失利", data: currChunk };
- return;
- },
- },
- }),
- // 解决响应
- async (ctx) => {
- ctx.set("Content-Type", "application/json");
- ctx.body = JSON.stringify({
- code: 2000,
- message: 'upload successfully!'
- });
- }
- );
整合分块
通过文件名找到对于应文件分块目录,应用 fs.readdirSync(chunkDir) 方法获取对于应目录下以是分块的命名,在通过 fs.createWriteStream/fs.createReadStream 建立可写/可读流,联合管道 pipe 将流整合在统一文件中,离开实现后通过 fs.rmdirSync(chunkDir) 删除了对于应分块目录。
- // 离开申请
- router.post('/mergeChunks', async (ctx) => {
- const { filename, size } = ctx.request.body;
- // 离开 chunks
- await mergeFileChunk(path.join(outputPath, '_' + filename), filename, size);
- // 解决响应
- ctx.set("Content-Type", "application/json");
- ctx.body = JSON.stringify({
- data: {
- code: 2000,
- filename,
- size
- },
- message: 'merge chunks successful!'
- });
- });
- // 通过管道解决流
- const pipeStream = (path, writeStream) => {
- return new Promise(resolve => {
- const readStream = fs.createReadStream(path);
- readStream.pipe(writeStream);
- readStream.on("end", () => {
- fs.unlinkSync(path);
- resolve();
- });
- });
- }
- // 离开切片
- const mergeFileChunk = async (filePath, filename, size) => {
- const chunkDir = path.join(outputPath, filename);
- const chunkPaths = fs.readdirSync(chunkDir);
- if (!chunkPaths.length) return;
- // 依据切片下标停止排序,否则间接读取目录的获取的程序能够会错乱
- chunkPaths.sort((a, b) => a.split("-")[1] - b.split("-")[1]);
- console.log("chunkPaths = ", chunkPaths);
- await Promise.all(
- chunkPaths.map((chunkPath, index) =>
- pipeStream(
- path.resolve(chunkDir, chunkPath),
- // 指定地位建立可写流
- fs.createWriteStream(filePath, {
- start: index * size,
- end: (index + 1) * size
- })
- )
- )
- );
- // 离开后删除了生存切片的目录
- fs.rmdirSync(chunkDir);
- };
前端&效劳端交互
前端分块上传
测试文件信息:
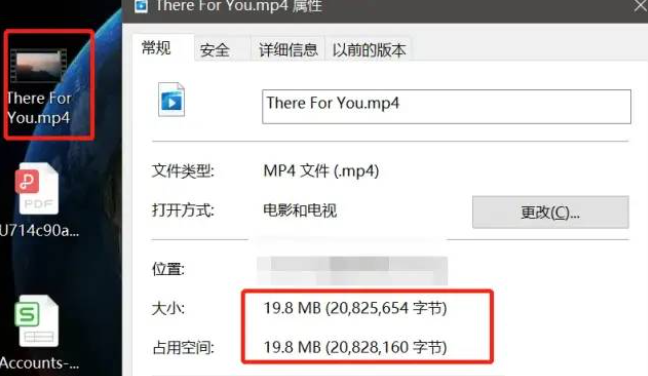
抉择文件范例为19.8MB,而且下面设定默认分块巨细为5MB,因而应当要分成4个分块,即4个申请。
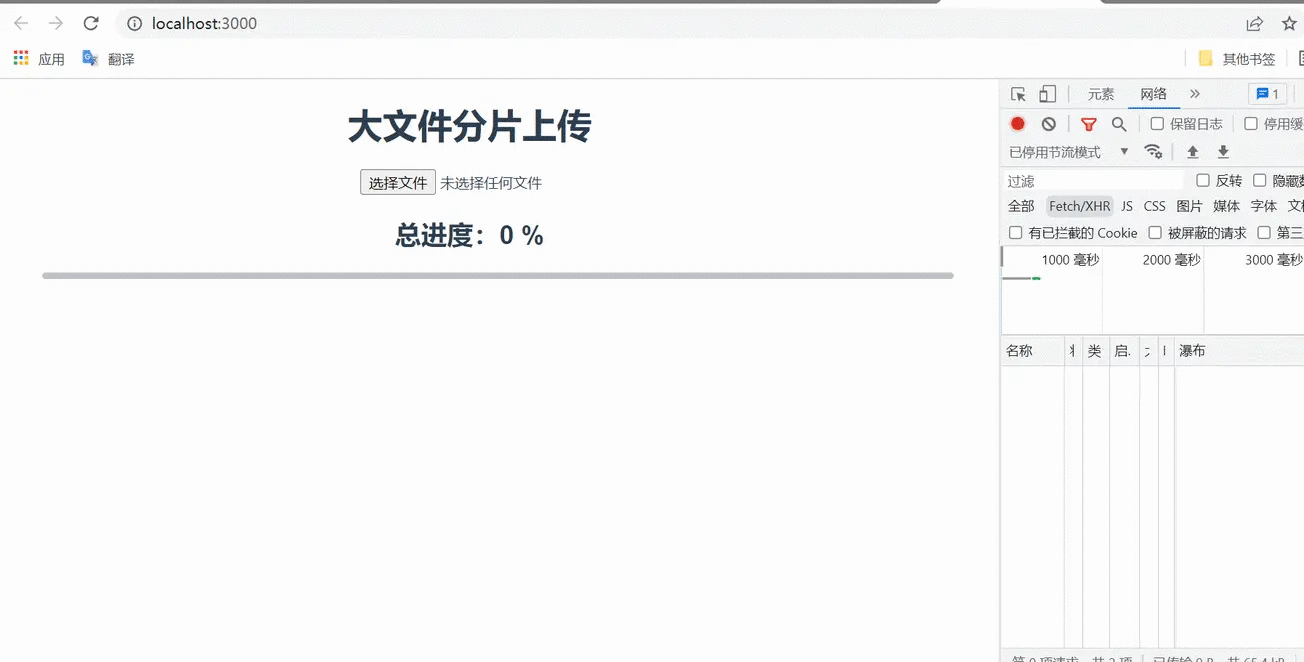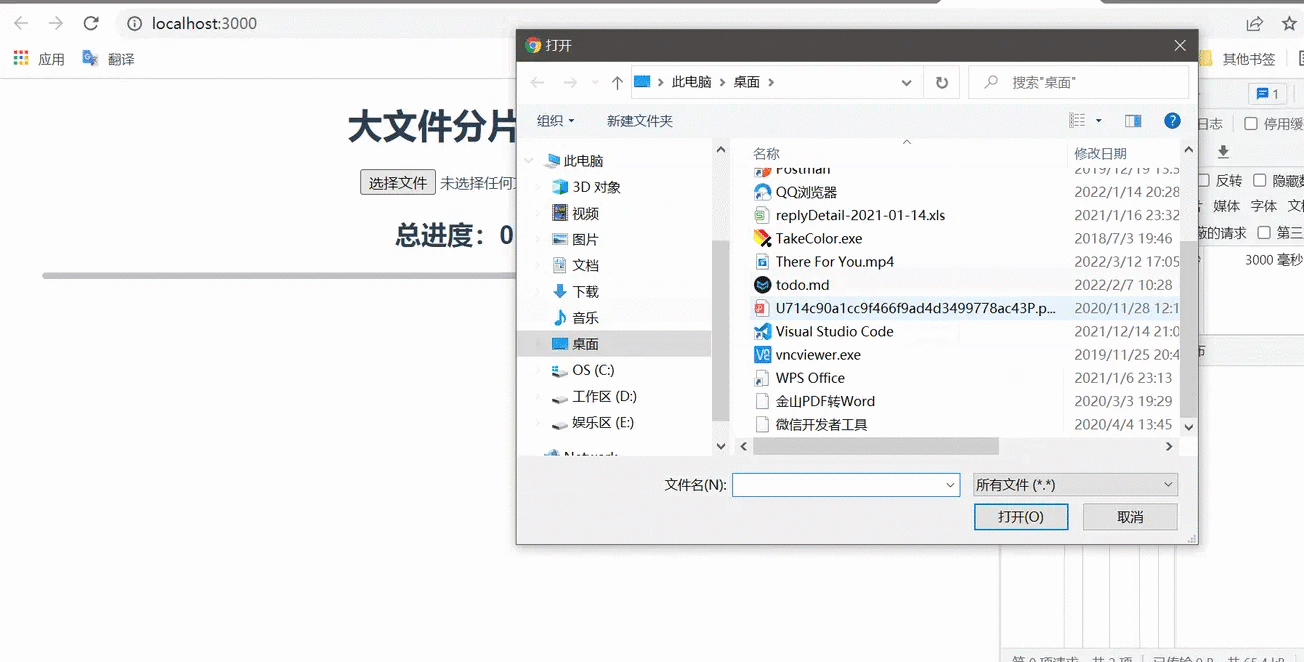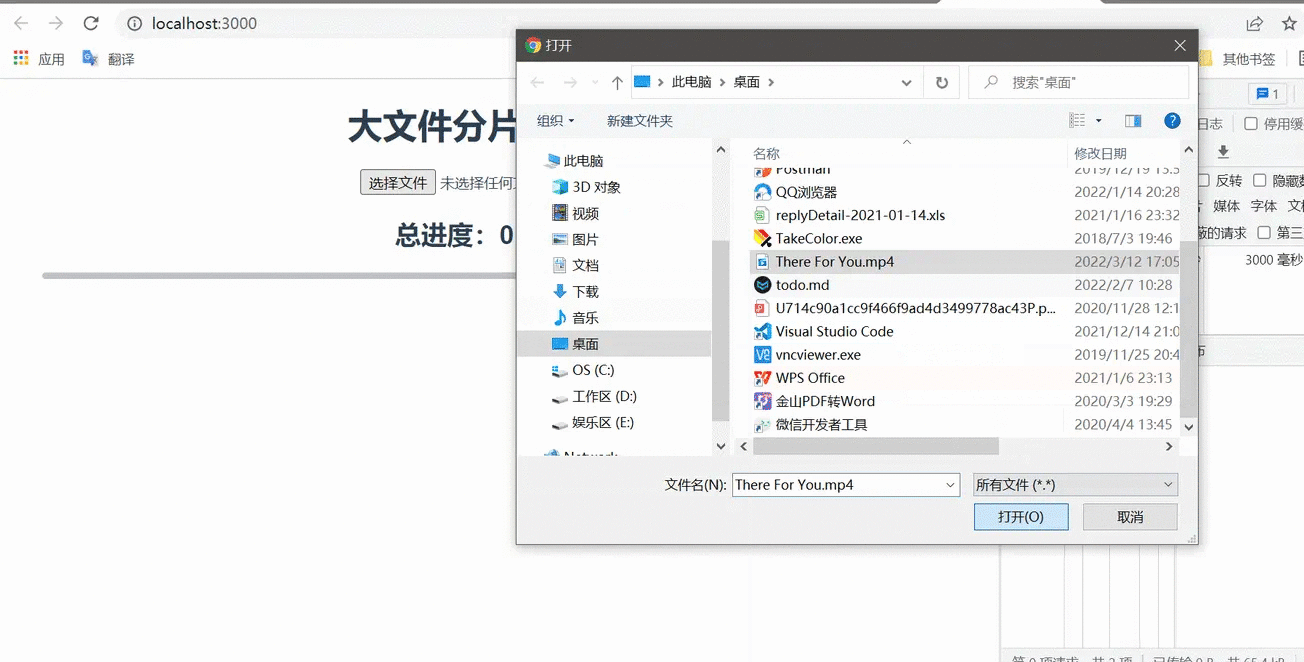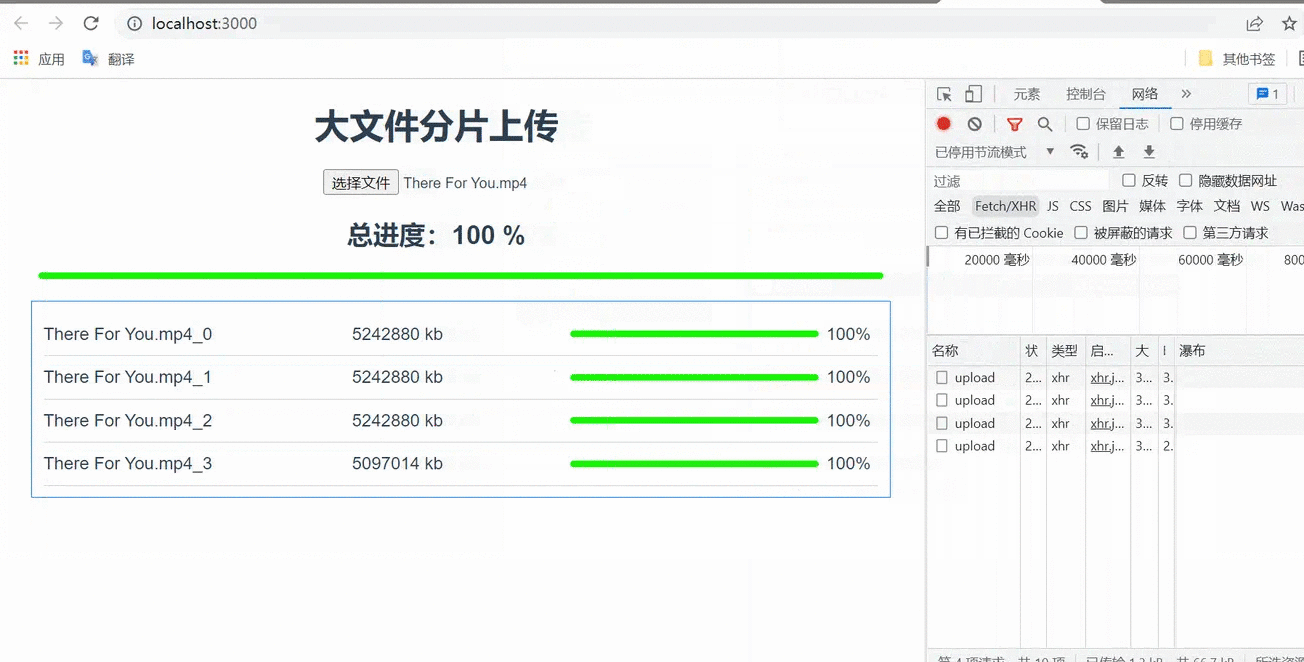
效劳端分块接受
前端发送离开申请
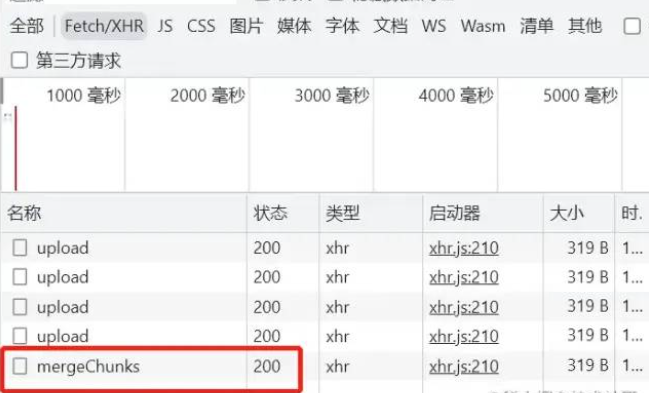
效劳端离开分块
扩年夜——断点续传&秒传
有了下面的外围逻辑以后,要实现断点续传以及秒传的性能,只要要在取扩年夜就可,这里再也不给出细致实现,只列出一些思路。
断点续传
断点续传实在便是让申请可中断,而后在接着上次中断的地位连续发送,此时要生存每一个申请的实例工具,以便前期废除了对于应申请,并将废除了的申请生存或者记载原始分块列表废除了地位信息等,以便前期从新发起申请。
废除了申请的多少种形式:
如果应用原生XHR可应用 (new XMLHttpRequest()).abort() 废除了申请
如果应用axios可应用 new CancelToken(function (cancel) {}) 废除了申请
如果应用fetch可应用 (new AbortController()).abort() 废除了申请
秒传
不要被这个名字给误导了,实在所谓的秒传便是不用传,在正式发起上传申请时,先发起一个检察申请,这个申请会照顾对于应的文件hash给效劳端,效劳端卖命查找是否存在年夜同小异的文件hash,如果存在此时间接复用这个文件资本就可,不需要前端在发起分外的上传申请。
本文链接:https://addon.ciliseo.com/da-wen-jian-zen-me-kuai-su-shang-chuan-zui-shi-yong-de-shi-xian-fang-fa.html







网友评论