
一淘模板给人人带来了对于于Python的相干知识,主要介绍了Python怎样用NumPy读取以及生存点云数据,文章环抱主题开展细致的内容介绍,拥有一定的参考价钱,需要的小伙伴能够参考一下。

最近在深造点云解决的时刻用到了Modelnet40数据集,该数据集总共有40个种别,每一个样本的点云数据寄存在一个TXT文件中,每一行的前3个数据代表一个点的xyz坐标。我需要把TXT文件中的每一个点读掏进去,而后用Open3D停止显示。怎么把数据从TXT文件中读掏进去呢?NumPy供应了一共性能非常强年夜的函数loadtxt能够非常轻易地实现这共性能。来看一下代码:
import open3d as o3dimport numpy as np def main():points_data = np.loadtxt("airplane_0001.txt", delimiter=",", dtype=np.float32)pcd = o3d.geometry.PointCloud()pcd.points = o3d.utility.Vector3dVector(points_data[:, :3])o3d.visualization.draw_geometries([pcd]) if __name__ == '__main__':main()从下面的代码能够看到,只要要一行代码就能够把TXT文件中的点云数据读取进来了,接下来就能够调用Open3D的接口停止显示了。在介绍loadtxt函数的用法以前,
特地看一下Open3D的显示效果:
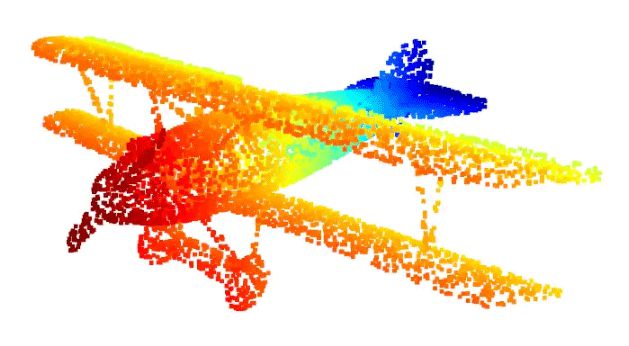
基础用法
在下面的例子中,因为TXT外面每一行的数据是用逗号宰割的,以是在调用loadtxt函数的时刻除了配置文件门路外,还需要配置参数delimiter=","。此外,该函数默认的数据范例为float64,如果是其余数据范例的话还需要配置dtype为对于应范例。
points_data = np.loadtxt("airplane_0001.txt", delimiter=",") #不指定命据范例print('shape: ', points_data.shape)print('data type: ', points_data.dtype)效果:
shape:(10000,6)
datatype:float64
指定每一列的数据范例
倘若咱们有一个CSV文件:
x,y,z,label,id-0.098790,-0.182300,0.163800,1,10.994600,0.074420,0.010250,0.2,20.189900,-0.292200,-0.926300,3,3-0.989200,0.074610,-0.012350,4,4该文件前面3列的数据范例是浮点型,前面2列的数据范例为整型,那末遵循前面的形式配置dtype来读取就不适宜了。无非不妨,loadtxt函数能够配置每一列数据的数据范例,只无非细微简繁多点,来看一下代码:
data = np.loadtxt("test.txt", delimiter=",",dtype={'names': ('x', 'y', 'z', 'label', 'id'), 'formats': ('f4', 'f4', 'f4', 'i4', 'i4')},skiprows=1)print('data: ', data)print('data type: ', data.dtype)这段代码的重点是dtype={}外面的内容,'names'用来配置每一列数据的名称,'formats'则用来配置每一列数据的数据范例,其中'f4'示意float32,'i4'示意int32。此外,CSV文件中的第一行不是数据内容,能够配置参数skiprows=1跳过第一行的内容。
输入效果:
data:[(-0.09879,-0.1823,0.1638,1,1)(0.9946,0.07442,0.01025,0,2)
(0.1899,-0.2922,-0.9263,3,3)(-0.9892,0.07461,-0.01235,4,4)]
datatype:[('x','






网友评论
断桥念雪
回复Python编程中,使用NumPy读取和保存点云数据教程简单易懂、高效实用!